精度、スピード、コストで優位。 3万以上のデータで検証、文字認識エンジンの開発
精度、スピード、コストで優位。 3万以上のデータで検証、文字認識エンジンの開発
「DEEP READ」は、AIを活用した文字認識技術を用いた手書き文字テキストデータ化サービス。ディープラーニング(深層学習)を応用することにより、AIが自動でデータに変換。従来型のOCR(光学的文字認識)や通常のデータ入力と比較して、精度、スピード、コストで圧倒的な優位性を得ています。殴り書きしたような文字も含め、約3万5000点の手書きテストデータを検証したところ、人力でデータ入力した際の精度である平均93%を上回る94.5%の精度を実現しています。


DEEP READ担当執行役員 / DoubleYard Inc. CEO
安永 達矢
中国上海市出身。中学一年からプログラミングを始め、高校卒業後に日本に単身留学。2002年、東京大学大学院電子情報工学科修士課程修了。卒業後、SAPジャパン株式会社に入社。日本、ドイツ、アメリカで大規模システムの開発を経験し、数々のプロジェクトのリーダーを務める。2011年iDeep Solutionsに入社し、大規模遠隔会議システムの研究開発を主導。2016年4月EDUTECH LAB AP PTE. LTD.(シンガポール)に参画し、AI製品の開発リードを担当。現在は株式会社EduLabのVice Presidentとして、技術力および日中英3ヶ国語を駆使してAI事業を統括。
テクノロジーを駆使し、労働集約的であった作業の効率化を実現
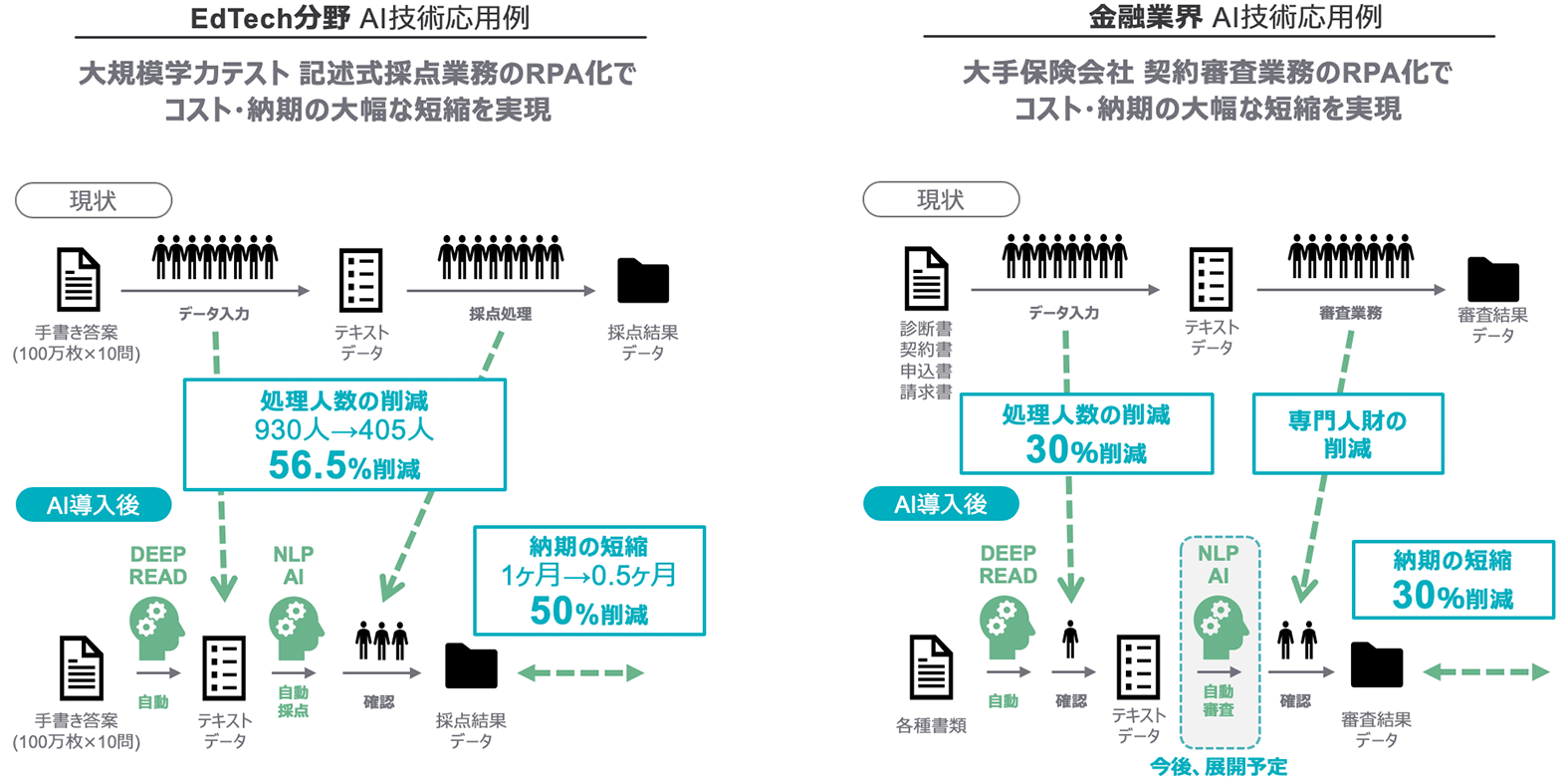
EduLabグループでは、前身の教育測定研究所の事業を含め、約15年前から100万人規模のテスト採点業務を受託し、膨大な答案を分析してきました。
DEEP READ開発の背景にあったのは、かねてからの課題であった答案の採点にかかる膨大な時間と費用の削減。そしてもう一つ、2020年の大学入試センター試験から、マークシートのような選択式ではなく記述式の答案が増えることで、さらに自動採点化の必要性が高まる点が挙げられます。
文字認識そのものは、OCR技術を活用して既に多くの企業が取り組んできました。従来型のOCR技術では、様々なフォントの活字をデータベース化することで、活字については高い精度でデータ化を可能にしています。しかし、新しいフォントには対応できなかったり、形にばらつきがある手書き文字の認識精度は低いため、手書き文字については人力による打ち込み(パンチ入力)作業に頼ったデータ化が一般的でした。
多くの企業や団体が、手書き文字の入力作業を海外などにBPO(外部委託)しており、そのために膨大な時間的・費用的コストがかけられています。
保険会社や病院、金融系会社など、顧客データや各種申込書などの膨大なデータを紙で管理している企業・団体は多数存在します。
私たちは自社の教育コンテンツや採点業務の効率化はもとより、こうした問題を解決するために、約2年前からAI文字認識の研究開発を開始しました。
文字認識精度は平均94.5%、平均で83%の作業時間をカット
DEEP READは、従来型のOCR技術とは一線を画す、ディープラーニングに基づくAI(人工知能)を活用した文字認識技術です。
開発にあたり、当初は競合他社と同様1文字ずつ認識をさせてみましたが、手書き文字の場合、文字同士の境界が不明瞭だったり、2、3文字全部つながってしまっていることもあります。また、罫線がある場合は枠線にかかっていると文字を分けるのが難しくなります。
さらに、例えばカタカナの「チ」と漢字の「千」、カタカナの「ユ」と漢字の「コ」など、殴り書きでは特に判別しにくくなる文字は無数にあります。
そこで編み出したのが、1文字だけでなく前後のテキストも含めて認識させる方法。
文章の流れや文字の関係などから類推して手書き文字を認識していく。極めて人間が見ている時と同じ流れで文章のコンテキスト(文脈)をAIに学習させることで、手書き文字認識の精度を高めることに成功しました。

また、漢字は「へん」と「つくり」の組み合わせにより構成されるため、一文字づつに切り取った読み取りだと、例えば「林」を「木」「木」と読んでしまうなどの課題がありました。こういった点もAIによるアプローチで徐々に改善し、現在では非常に高精度で複数文字の読み取りが可能となっています。

現在、DEEP READの文字認識精度は94.5%。競合他社の中には、より高い精度をアピールする企業もありますが、そもそも手書き文字検証データのサンプル数が少なく信憑性が低いものも少なくありません。
DEEP READの精度は金融、教育、官公庁などあらゆる業界の3万5千点のテストデータを使って検証したデータです。また、試験の解答についても当社の実際のお客様を使って検証を行い、圧倒的に高い数値を出しています。
業種・職種を限定せず、幅広くサービスを模索
DEEP READは、教育分野においては、2020年に予定している学習指導要領の改訂を機に、今後ますます増加が予想される記述式答案の採点業務の効率化に大きく貢献することが見込まれます。
ほかにも銀行や保険の申込書、医療の診断書、クレジットカードの申し込み手続き、役所の各種申請手続きなど、近年の業務効率化や、データベースの有効活用の点からも紙データのデジタル化に対する需要は年々拡大しており、市場規模は大きいと考えています。
現在DEEP READは、英語版も展開。アルファベットのみのため日本語よりも精度は高く、平均97%の精度を実現しています。今後は欧米だけでなく、中国やインドでも展開をしていく予定です。
私たちは文字認識を一つの技術として、今後様々なパートナーと提携し、会社の業務効率に貢献するとともに、新たなサービス・製品を創出していきたいと考えています。
その他の事例
-

- 2018年12月28日 事業紹介
- 中国成長市場へ向けた塾事業の展開。 教室およびオンライン教育サービス「自習室」