Superior in accuracy, speed and cost, text recognition engine developed to verify more than 30,000 datasets
Superior in accuracy, speed and cost, text recognition engine developed to verify more than 30,000 datasets
“DEEP READ” is a text recognition service that utilizes AI text recognition to turn handwritten text into text data. By taking advantage of deep learning, its AI engine can automatically turning handwritten text into text data. It has been shown to be far superior to conventional OCR (Optical Character Recognition) and humans performing the same task in accuracy, speed, and cost. It has realized an accuracy rate of 94.5% when tested using about 35,000 handwritten detests that include scribbles, outperforming human data entry with an average accuracy rate of 93%.


Executive officer in charge of DEEP READ / DoubleYard Inc. CEO
Tatsuya Yasunaga
Born in Shanghai, China. Began programming when he was in the seventh grade and studied abroad by himself in Japan following graduation from high school. Graduated from the Graduate School of Information Science and Technology, The University of Tokyo, with a master’s degree in 2002. Joined SAP Japan, Inc. after graduation. Worked on the development of large-scale systems in Japan, Germany, and the USA, serving as the head of many projects. Joined iDeep Solutions in 2011 and led the research and development of a large-scale remote conference system. Joined EDUTECH LAB AP PTE. LTD. (Singapore) in April, 2016, serving as the head of AI product development. Currently manages AI businesses as Vice President of EduLab, Inc. taking advantage of his technical skills as well as fluency in Japanese, Chinese, and English.
Made previously labor-intensive tasks more efficient through technology
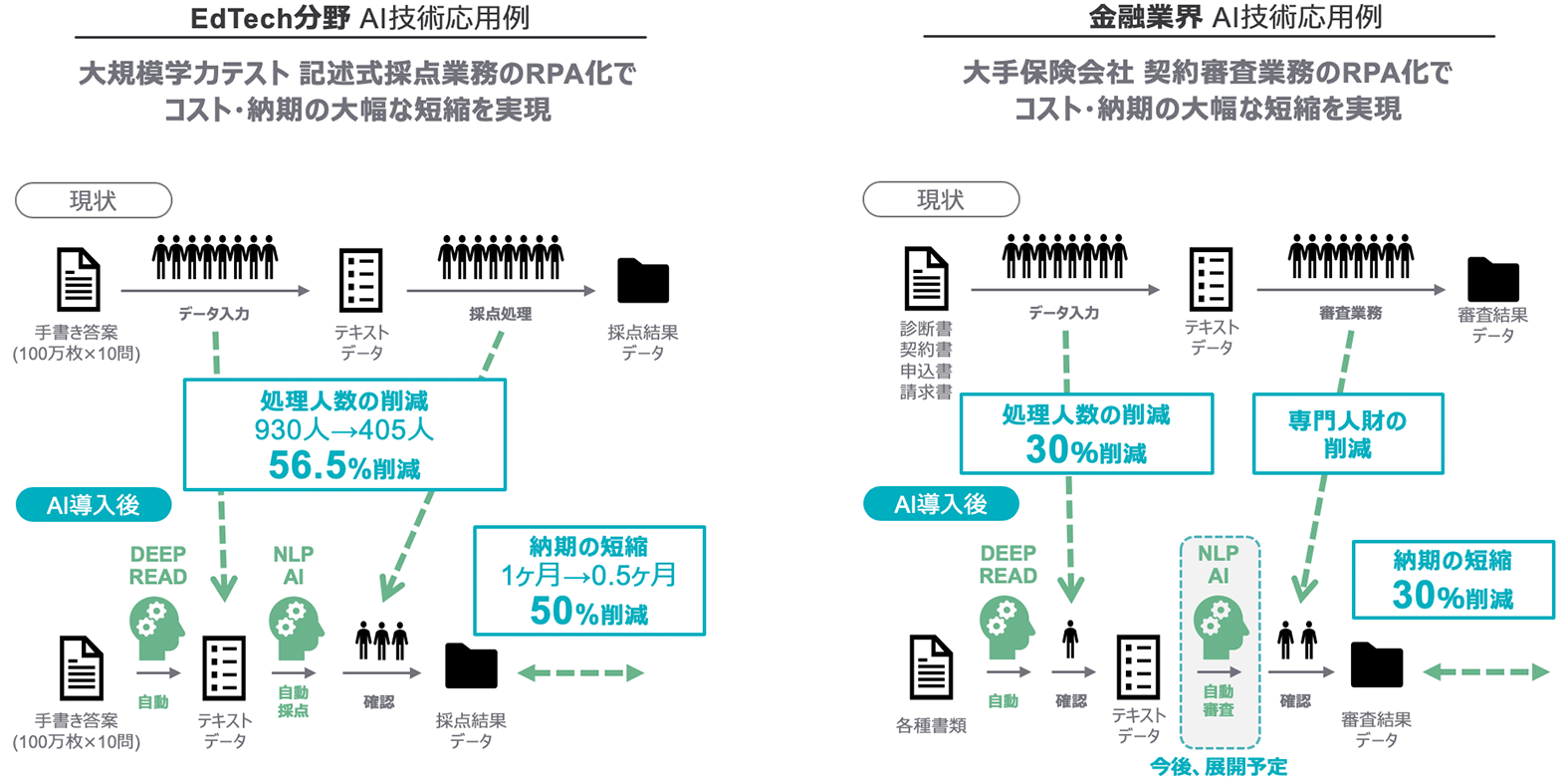
For the past 15 years or so, the EduLab group and its predecessor, The Japan Institute for Educational Measurement, Inc, have been analyzing a large amount of exam answers as a subcontractor, scoring tests submitted by 1 million examinees.
What we tried to achieve with DEEP READ was to reduce the large amount of time it takes to score tests and the cost associated with it, both of which had been an issue for a long time. Another thing that calls for such a system is the growing demand for further automation of scoring due to the introduction to the 2020 National Center Test for University Admissions of description-format questions in addition to multiple-choice questions.
Text recognition itself is an old technology that many enterprises have worked on using OCR technologies. Traditional OCR technologies achieve a high accuracy rate when it comes to analyzing printed text by creating a database of how characters are represented in various fonts. However, they cannot support new fonts and have a low accuracy rate when faced with handwritten text due to variations in character shapes. Therefore, it was common to rely on human keypunch operators for turning handwritten text into text data.
Many enterprises and organizations outsource keypunch operations of handwritten text to foreign service providers (BPO), which is both extremely time-consuming and costly.
Many enterprises and organizations, including insurance companies, hospitals, financial institutions, etc., store a large amount of data in paper format, such as customer data and various application forms.
We began to work on research and development of AI-based text recognition about two years ago with the aim of solving these issues, in addition to making our in-house educational content and scoring operations more efficient.
A text recognition system that is 5.88x faster on average, with an accuracy rate of 94.5% on average
DEEP READ is an AI-based text recognition technology that utilizes deep learning, a system that is distinctively different from traditional OCR technologies.
In the development phase, we initially tried to get the system to recognize the text character-by-character, just like our competitors were doing. However, when it comes to recognizing handwritten text, sometimes it is hard to see where one character ends and the next one begins, or sometimes two or three characters are written in one stroke. Also, when there are ruled lines, it gets more difficult to separate the characters that are written over them.
Moreover, there are countless combinations of characters that are hard to tell apart especially when written in a hurry, such as the katakana letter “チ” and the kanji character “千” or the katakana letters “ユ” and “コ.”
That is why we came up with a method where every character is recognized not on its own but together with the preceding and following text.
We successfully achieved a higher accuracy rate by constructing a system where the AI learns the context of the text in a way that is very similar to how humans read text, namely inferring each character from the context of the text and the relationship between the characters therein.

Also, since kanjis are composed of left and right components, when scanning a text character-by-character, the issue of misreading “林” for “木” “木,” etc., became apparent. This issue was also gradually solved using an AI-based approach, and now our system has achieved an extremely high accuracy rate when scanning multiple characters.

Currently, DEEP READ boasts an accuracy rate of 94.5% when analyzing text. Some competitors advertise a higher accuracy rate, but their figures are often times unreliable as they rely on a small amount of handwritten text data for testing.
DEEP READ’s figures were calculated by testing it using 35,000 datasets from numerous industries, including data from financial institutions, educational institutions, and government bodies. Also, we tested it using exam answers from our actual clients, achieving an overwhelmingly high accuracy rate.
Looking to expand our services to diverse industries and settings
DEEP READ is expected to contribute immensely to making scoring operations more efficient, as the 2020 renewal of curriculum guidelines will result in more and more description-format examinations being used in educational settings.
Moreover, the demand for the digitization of paper documents such as bank and insurance application forms, medical certificates, credit card application forms, various government applications, etc., is growing year by year. As the importance of efficiency and utilization of database is now being recognized, we believe that it represents a large market.
Currently, DEEP READ is also offered in English. Since English uses the Latin alphabet only, the English version boasts an accuracy rate of 97% on average, outperforming the Japanese version. We are planning to expand this service not only into Europe and America, but also into China and India.
Equipped with text recognition as one of our primary technologies, we are looking forward to collaborating with various partners in the future to contribute to making corporate operations more efficient and to creating new services and products.
